0,常用正则匹配规则
1 | ^ # 行首定位 |
1,通过实验来一个一个讲解以上规则的使用
2.1 “^”
匹配所有包含root的行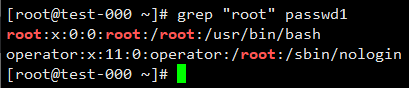
匹配以root开头的行
2.2 “$”
匹配所有包含sh的行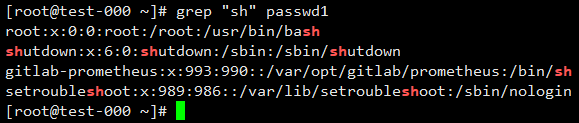
匹配以sh结尾的行
2.3 “.”
匹配任意4个结尾是”:”字符的行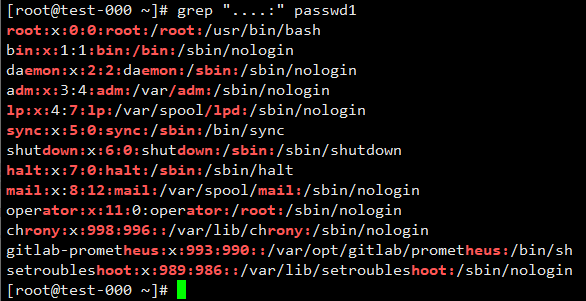
匹配行首任意4个带”:”字符的行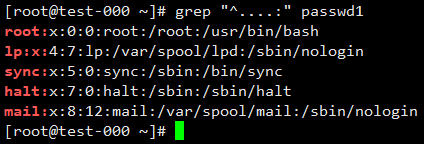
2.4 “*“
匹配0或多个b后面带in字符的行,可以看到下面可以没有b只有in也会被匹配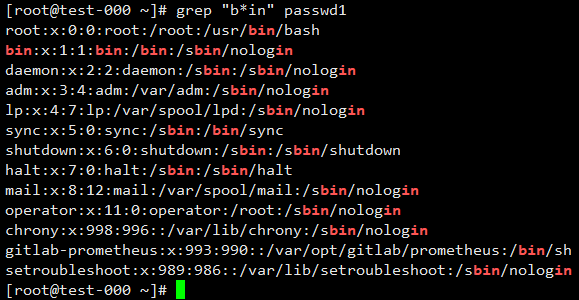
2.5 “+”
匹配一个或多个带数字9的行
用grep扩展正则的方式执行,不需要加转义符”"
2.6 “?”
匹配0次或1次o字符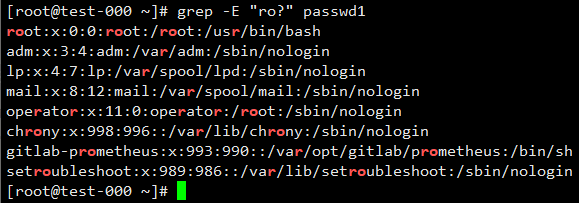
2.7 “[]”
匹配包含v|a|r字符的行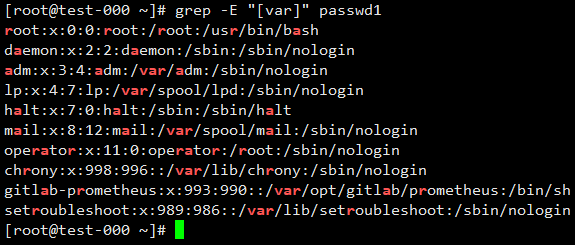
匹配所有包含数字的行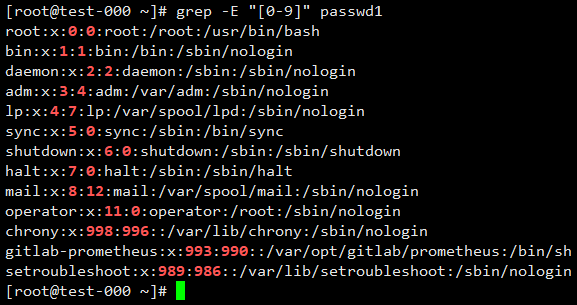
匹配所有非0-9的字符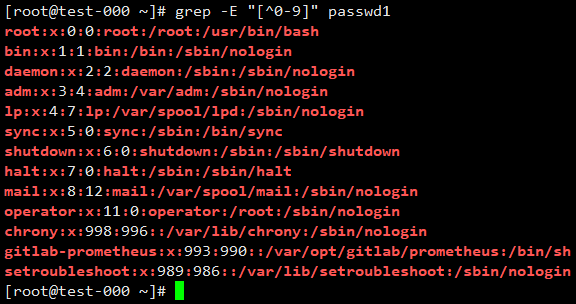
2.8 “< >“
匹配以r为词首的行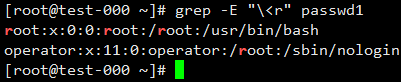
匹配以t为词尾的行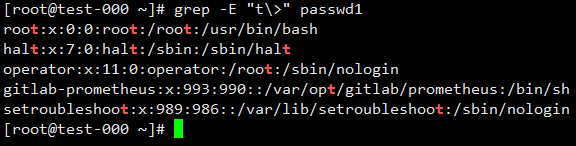
匹配以r为词首t为词尾的行
2.9 “{ }“
匹配连续出现2个o的行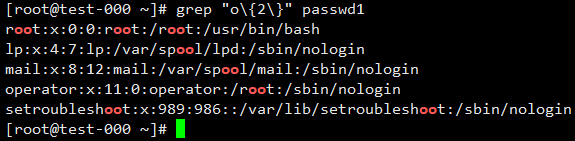
下面使用grep扩展正则的方式来执行,以达到节省转义符和保护视力的目的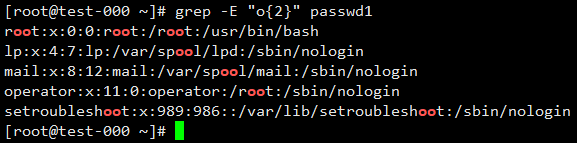
匹配至少出现2次”:”的行
匹配出现2次以上3次一下带”o”的行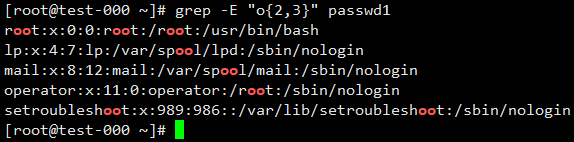
2.10 “( )“
匹配包含990或993的行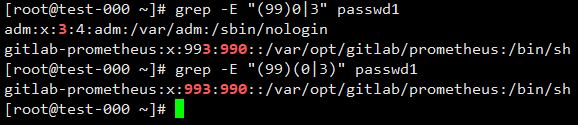
进行分组替换操作,第一个括号的内容可以用”\1”表示,第二个用”\2”表示,以此类推,最多为9个.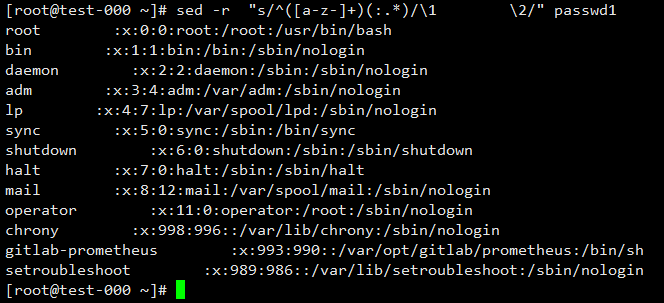
为了更容易理解,将\1 和 \2变换一下位置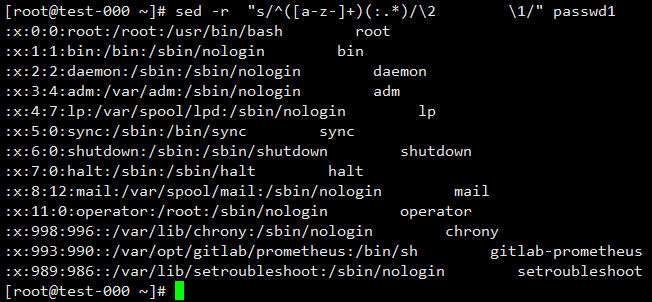
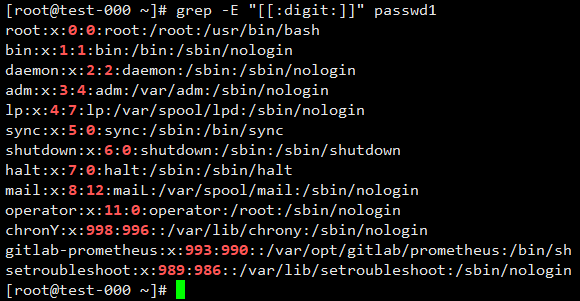
2.12 “[[:alpha:]] [[:lower:]] [[:upper:]] [[:digit:]]”
[[:alpha:]]匹配所有的字母,大小写都有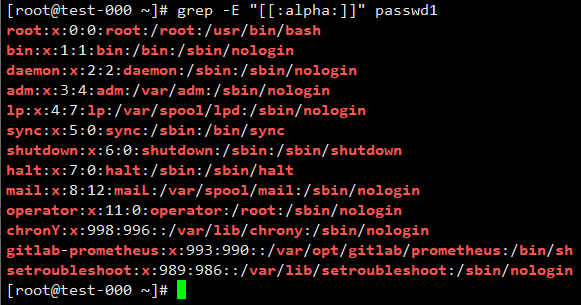
[[:lower:]]匹配所有的小写字母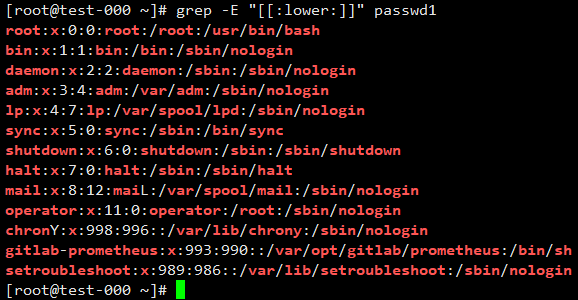
[[:upper:]]匹配所有大写字母
[[:digit:]]匹配所有数字